Lab6_DMA
This tutorial will show you how to use the Xilinx AXI DMA with PYNQ. It will cover adding the AXI DMA to a new Vivado hardware design and show how the DMA can be controlled from PYNQ.
Create a new project
Create a project, and add the ZYNQ PS block.
Add the source file
Please add the source file.
AXIS_Double.v
`timescale 1ns / 1ps
module AXIS_Double(
// Declare the attributes above the port declaration
(* X_INTERFACE_INFO = "xilinx.com:signal:reset:1.0 axis_reset_n RST" *)
// Supported parameter: POLARITY {ACTIVE_LOW, ACTIVE_HIGH}
// Normally active low is assumed. Use this parameter to force the level
(* X_INTERFACE_PARAMETER = "POLARITY ACTIVE_LOW" *)
input axis_reset_n, // (required)
// Declare the attributes above the port declaration
(* X_INTERFACE_INFO = "xilinx.com:signal:clock:1.0 axis_clk CLK" *)
// from the top BD.
(* X_INTERFACE_PARAMETER = "ASSOCIATED_BUSIF S_AXIS_Double, ASSOCIATED_RESET axis_reset_n, FREQ_HZ 125000000, FREQ_TOLERANCE_HZ 0" *)
input s_axis_clk, // (required)
// Declare the attributes above the port declaration
(* X_INTERFACE_INFO = "xilinx.com:signal:clock:1.0 axis_clk CLK" *)
// from the top BD.
(* X_INTERFACE_PARAMETER = "ASSOCIATED_BUSIF M_AXIS_Double, ASSOCIATED_RESET axis_reset_n, FREQ_HZ 125000000, FREQ_TOLERANCE_HZ 0" *)
input m_axis_clk, // (required)
// input [<left_bound>:0] <s_tdest>,
(* X_INTERFACE_INFO = "xilinx.com:interface:axis:1.0 S_AXIS_Double TDATA" *)
input [31:0] S_AXIS_Double_TDATA, // Transfer Data (optional)
// (* X_INTERFACE_INFO = "xilinx.com:interface:axis:1.0 <interface_name> TSTRB" *)
// input [31:0] <s_tstrb>,)
(* X_INTERFACE_INFO = "xilinx.com:interface:axis:1.0 S_AXIS_Double TKEEP" *)
input [3:0] S_AXIS_Double_TKEEP,
(* X_INTERFACE_INFO = "xilinx.com:interface:axis:1.0 S_AXIS_Double TLAST" *)
input S_AXIS_Double_TLAST,
// (* X_INTERFACE_INFO = "xilinx.com:interface:axis:1.0 <interface_name> TUSER" *)
// input [31:0] <s_tuser>,
(* X_INTERFACE_INFO = "xilinx.com:interface:axis:1.0 S_AXIS_Double TVALID" *)
input S_AXIS_Double_TVALID,
(* X_INTERFACE_INFO = "xilinx.com:interface:axis:1.0 S_AXIS_Double TREADY" *)
output S_AXIS_Double_TREADY,
//MAXIS
(* X_INTERFACE_INFO = "xilinx.com:interface:axis:1.0 M_AXIS_Double TDATA" *)
output [31:0] M_AXIS_Double_TDATA,
// (* X_INTERFACE_INFO = "xilinx.com:interface:axis:1.0 <interface_name> TSTRB" *)
// input [31:0] <s_tstrb>
(* X_INTERFACE_INFO = "xilinx.com:interface:axis:1.0 M_AXIS_Double TKEEP" *)
output [3:0] M_AXIS_Double_TKEEP,
(* X_INTERFACE_INFO = "xilinx.com:interface:axis:1.0 M_AXIS_Double TLAST" *)
output M_AXIS_Double_TLAST, // Packet Boundary Indicator (optional)
// (* X_INTERFACE_INFO = "xilinx.com:interface:axis:1.0 <interface_name> TUSER" *)
// input [31:0] <s_tuser>
(* X_INTERFACE_INFO = "xilinx.com:interface:axis:1.0 M_AXIS_Double TVALID" *)
output M_AXIS_Double_TVALID,
(* X_INTERFACE_INFO = "xilinx.com:interface:axis:1.0 M_AXIS_Double TREADY" *)
input M_AXIS_Double_TREADY
// additional ports here
);
// user logic here
assign M_AXIS_Double_TDATA = S_AXIS_Double_TDATA << 1;
assign M_AXIS_Double_TKEEP = S_AXIS_Double_TKEEP;
assign M_AXIS_Double_TLAST = S_AXIS_Double_TLAST;
assign M_AXIS_Double_TVALID = S_AXIS_Double_TVALID;
assign S_AXIS_Double_TREADY = M_AXIS_Double_TREADY;
endmodule
Back to the source window, right-click AXIS_Double and choose Add Module to Block Design.
Adding the DMA
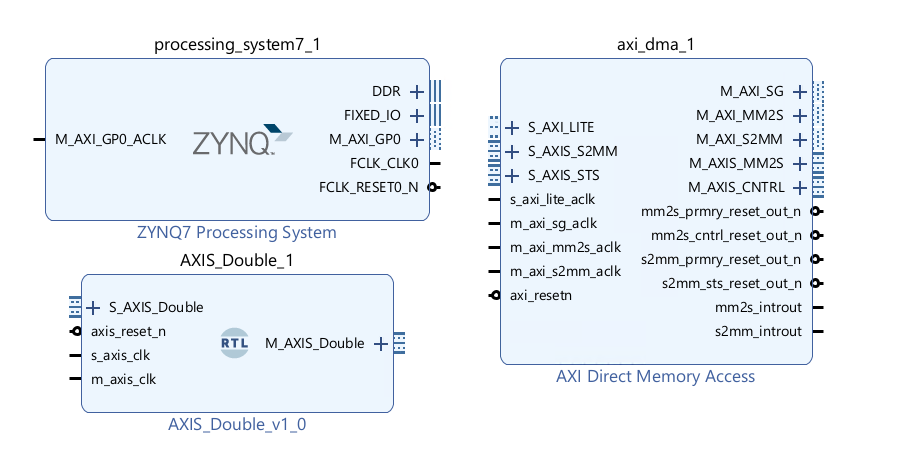
In the block diagram, which should contain the ZYNQ PS block, add the AXI Direct Memory Access block to your design.
DMA background
The DMA allows you to stream data from memory, PS DRAM in this case, to an AXI stream interface. This is called the READ channel of the DMA. The DMA can also receive data from an AXI stream and write it back to PS DRAM. This is the WRITE channel.
The DMA has AXI Master ports for the read channel and another for the write channel, which are also referred to as memory-mapped ports - they can access the PS memory. The ports are labeled MM2S (Memory-Mapped to Stream) and S2MM (Stream to Memory-Mapped). You can consider these as the read or write ports to the DRAM for now.
Control port
The DMA has an AXI lite control port. This is used to write instructions to configure, start and stop the DMA and readback status.
AXI Masters
There are two AXI Master ports that will be connected to the DRAM. M_AXI_MM2S (READ channel) and M_AXI_S2MM (WRITE channel). AXI masters can read and write the memory. In this design, they will be connected to the Zynq HP (High Performance) AXI Slave ports. The width of the HP ports can be changed in the Vivado design however, these ports are configured when PYNQ boots the board. You need to make sure the width of the ports in your Vivado design matches the PYNQ boot settings. In all official PYNQ images, the width of the HP ports is 64-bit.
If you set the HP ports to 32-bit if your design by mistake, you will likely see only 32-bits out of every 64-bits are transferred correctly.
AXI Streams
There are two AXI stream ports from the DMA. One is an AXI master Stream (M_AXIS_MM2S) and corresponds to the READ channel. Data will be read from memory through the M_AXI_MM2S port and sent to the M_AXIS_MM2S port (and onto the IP connected to this port).
The other AXI stream port is an AXI Slave (S_AXIS_S2MM). This is connected to your IP. The DMA receives AXI stream data from the IP and writes it back to memory through the M_AXI_S2MM port.
If the IP is not ready to receive data from the M_AXIS port, then this port will stall. You can also use AXI Stream FIFOs. If the IP tries to write back data but a DMA write has not started, the S_AXIS channel will stall the IP. Again, FIFOs can be used if required. The DMA has some built-in buffering, so if you are trying to debug your design, you may see some (or all) data is read from memory, but it may not necessarily have been sent to your IP and may be queued internally or in the HP port FIFOs.
Simply DMA support
PYNQ doesn’t support the gather functionality of the DMA. This is where data can be transferred from fragmented or disjointed memory locations. PYNQ only supports DMA from contiguous memory buffers
Scatter-Gather can be enabled on the DMA to allow multiple transfers of up to 8,388,608 bytes (from contiguous memory buffers). If you do this, you need to use the SG M_AXI ports instead of the M_AXI ports.
An alternative to SG for large transfers is to segment your memory transfers in software into chunks of 67,108,863 or less and run multiple DMA transfers.
Configure the DMA
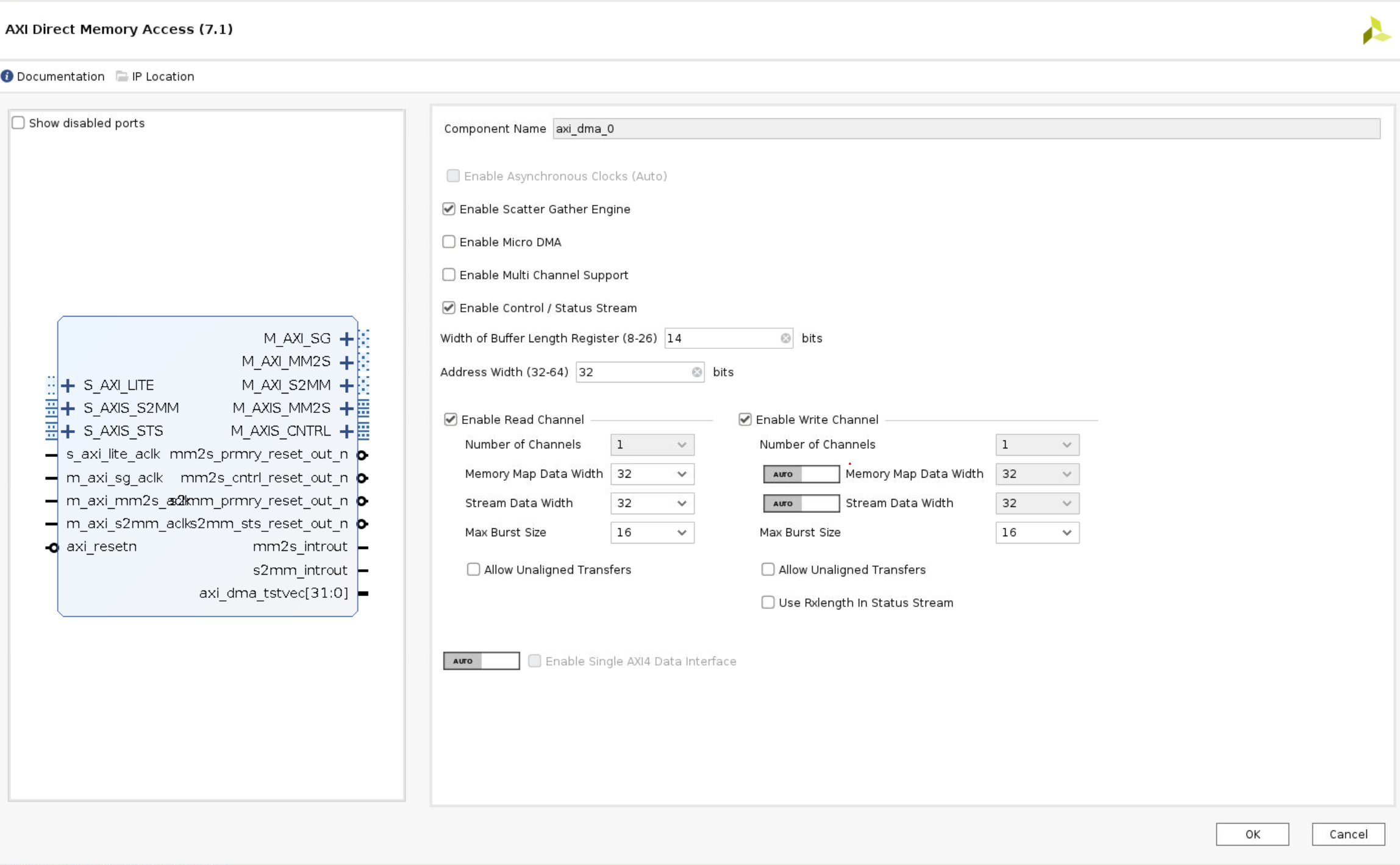
- Double-click the DMA to open the configuration settings
-
Uncheck Enable Scatter Gather Engine to disable Scatter Gather
-
Set the Width of the Buffer Length Register to 26
This value determines the maximum packet size for a single DMA transfer. Width = 26 allows transfers of 67,108,863 bytes - the maximum size the DMA supports. I usually set this value to the maximum value of 26. If you know you will never need more than a smaller size transfer, you can set this to a smaller value and save a small amount of PL resources. I prefer to set the maximum value for flexibility as the hardware resource increase is relatively modest.
When using the DMA if you try to do a transfer but only see that the first part of your buffer is transferred, check this value in your hardware design and check how much data you are transferring. Leaving the default with set to 14-bits is a common mistake which will limit the DMA to 16,384 byte transfers. If you try to send more than this the transfer will terminate once the maximum number of bytes supported is transferred. Remember to check the size of the transfer in bytes.
-
Check the address width is set to 32. In this example, I will connect the DMA to the PS memory which is 32-bit for Zynq. You can set this up to 64-bit if you are connecting this to a larger memory, for example, if you are using a Zynq Ultrascale+ or if your DMA is connected to a PL connected memory.
-
For this design, leave both read and write channels enabled
-
Set the memory-mapped data width to 64 matches the HP port (defined in the PYNQ image and applied at boot time)
-
Set the stream data to match your IP stream width. In this example, I will leave it set to 32.
-
Make sure Allow unaligned transfers is NOT enabled
-
Click OK to accept the changes
Connect the DMA
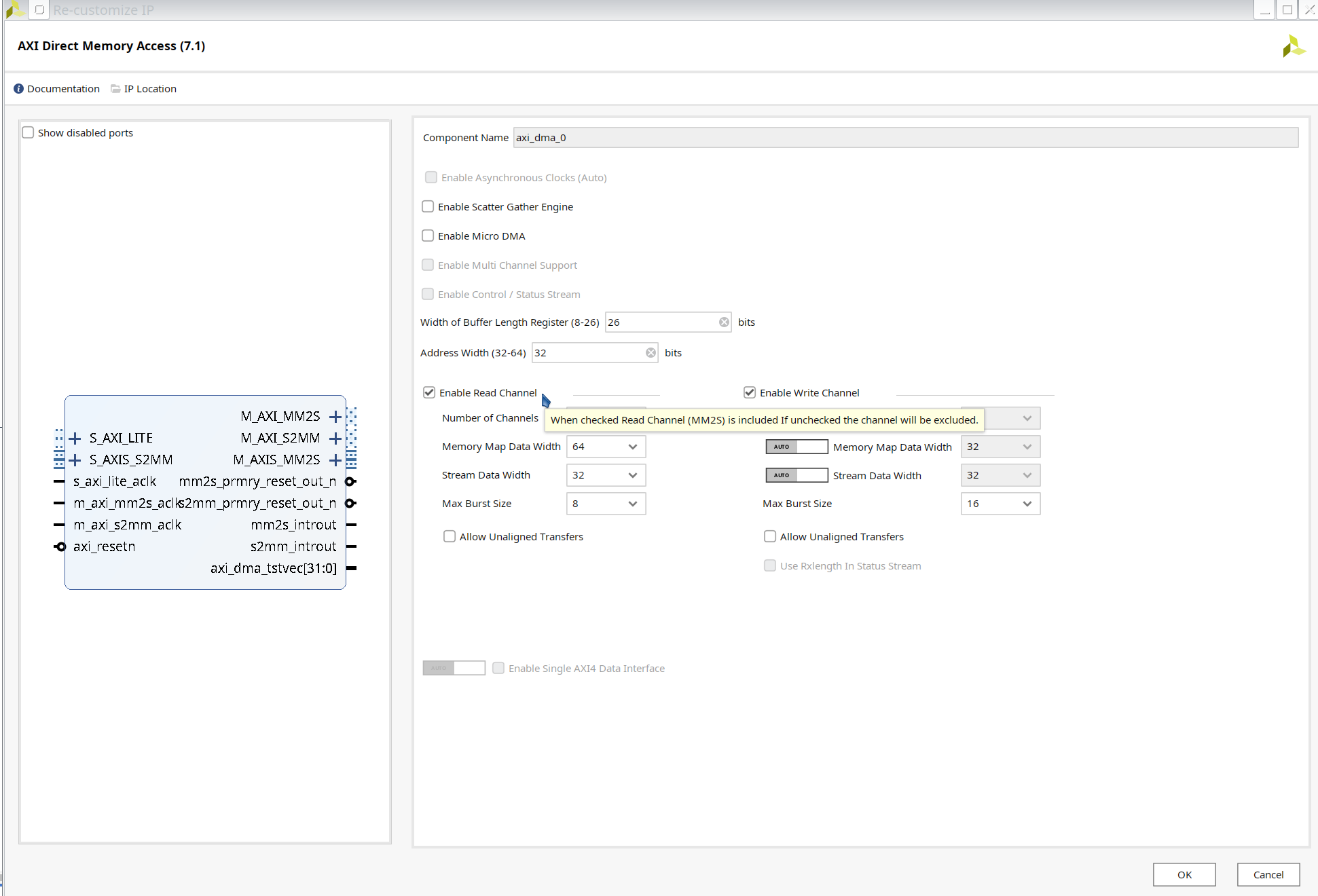
- Double click
ZYNQ7 Processing System, PS-PL Configuration > HP Slave AXI Interface > Select S AXI HP0 Interface.
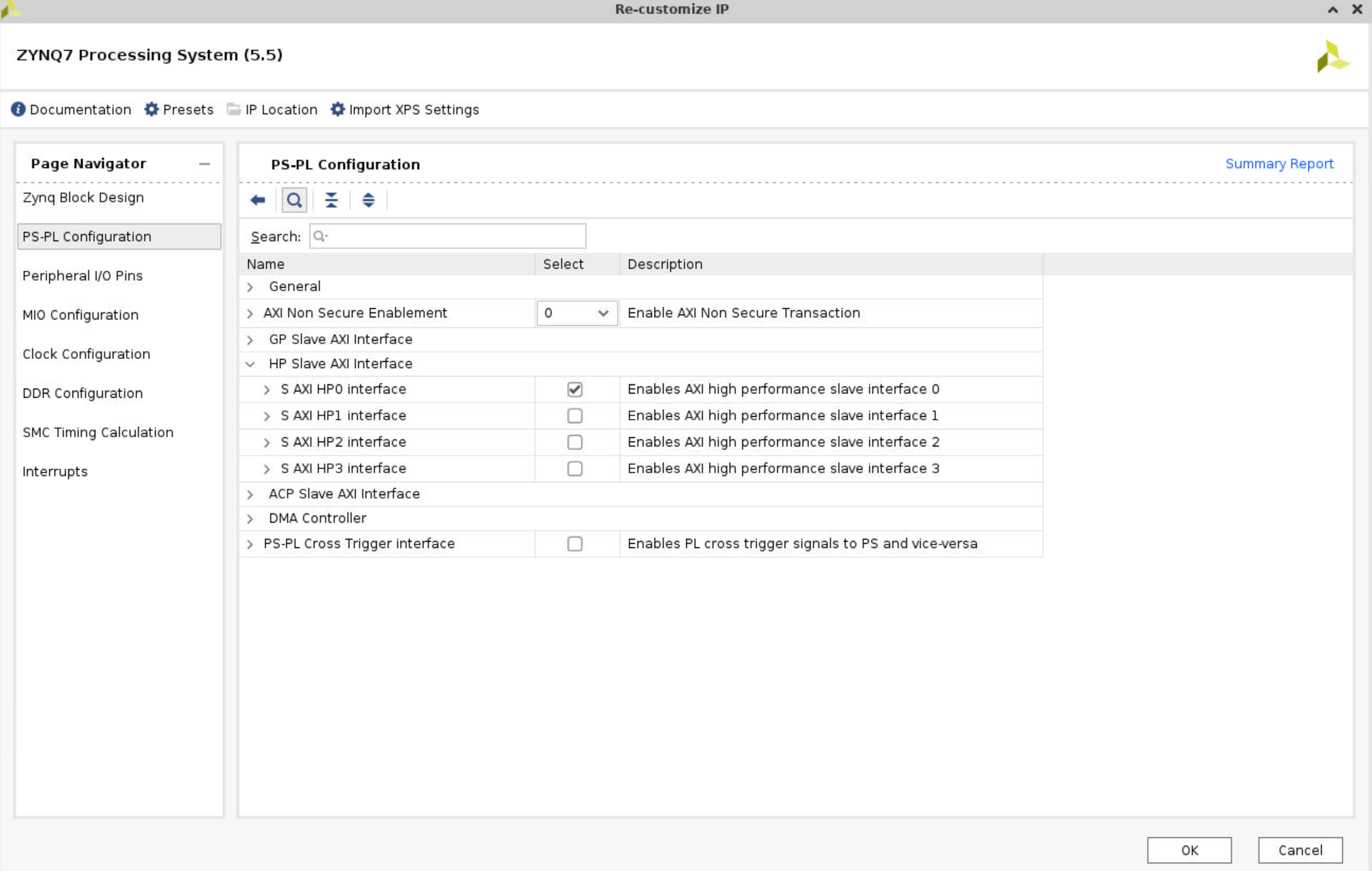
- Add
Clocking Wizard, double click it. In the Board option, change the Board Interface in the CLK_IN1 row tosys clock.
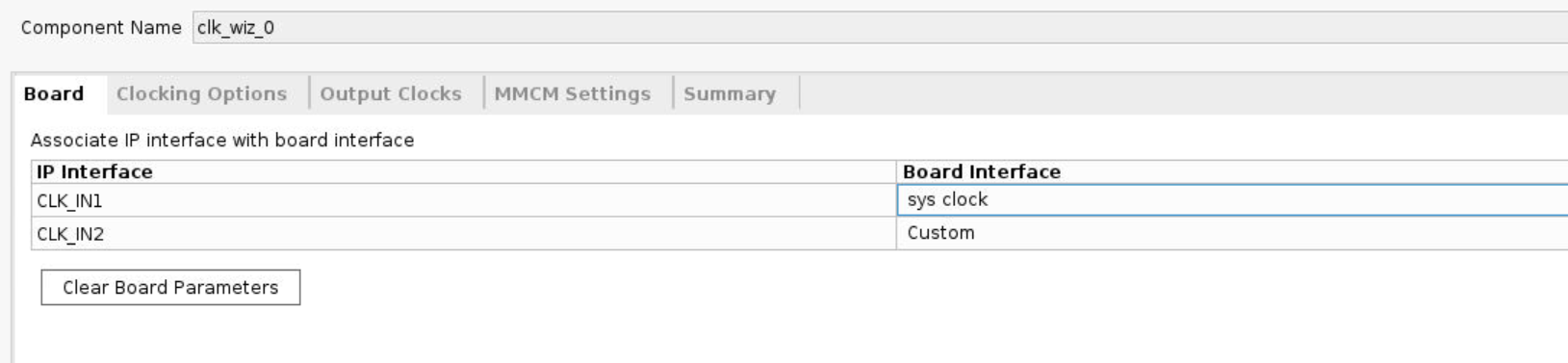
-
In the Output Clocks option, change the output frequency to 125M Hz.
-
Disable the
resetunder the output Clocks options. Connect thelockedport to theext_reset_inofProcessor System Reset. -
Click
Run Block AutomationandRun connection automation.
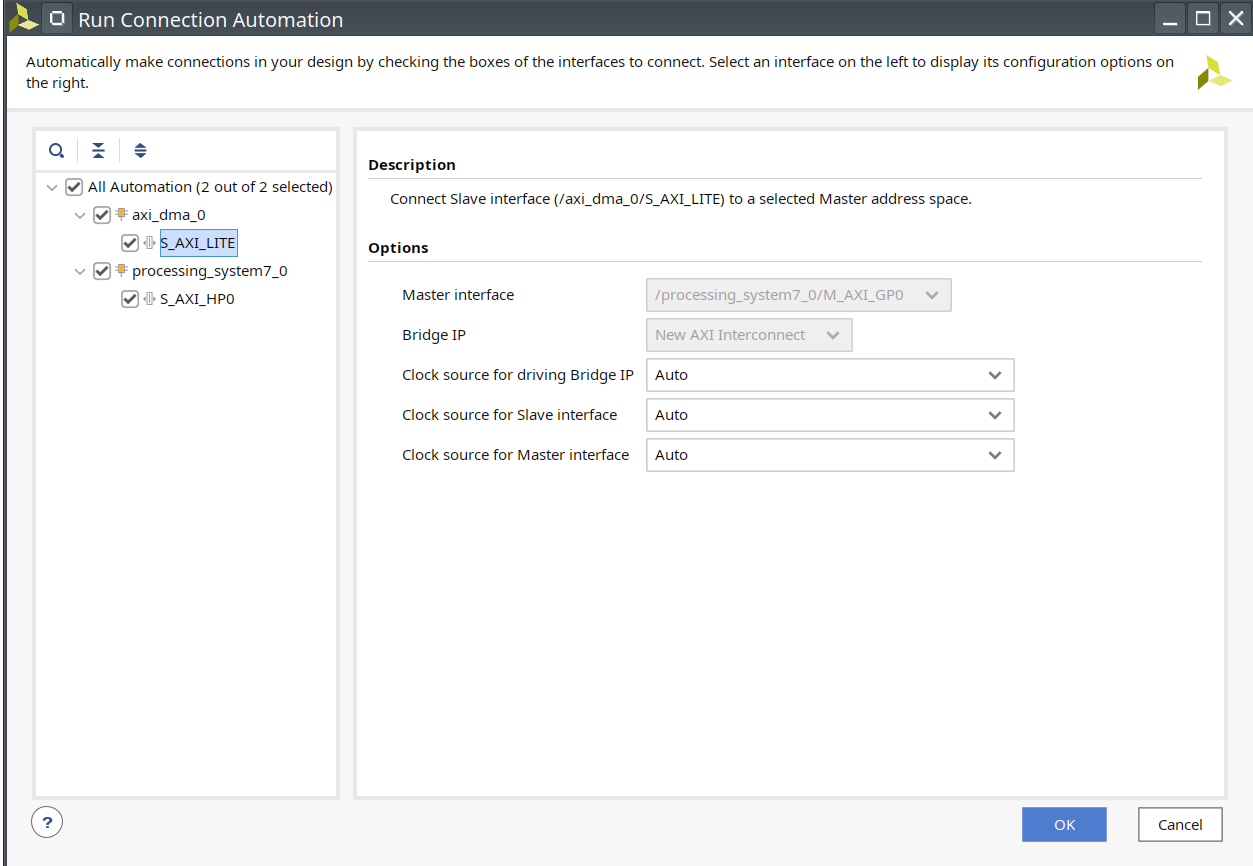
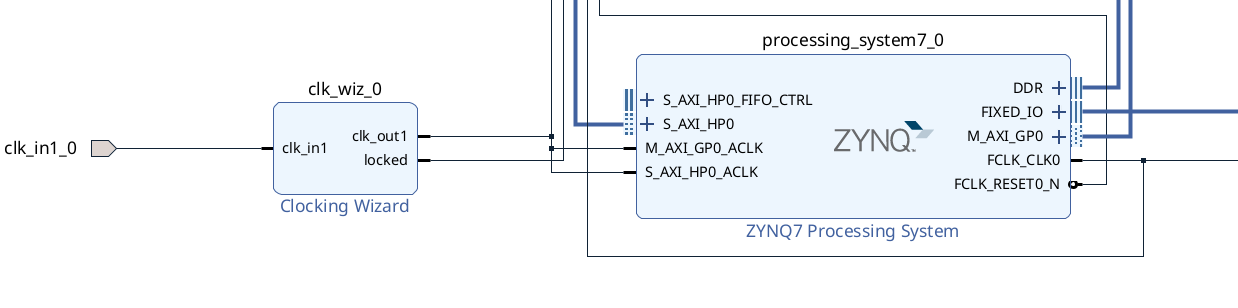
- Delete the orange line shown in the following figure, and connect the
clk_out1to theM_AXI_GP0_ACLKandS_AXI_HP0_ACLKofZYNQ7 Processing System. Then clickRun Connection Automation.
- Click
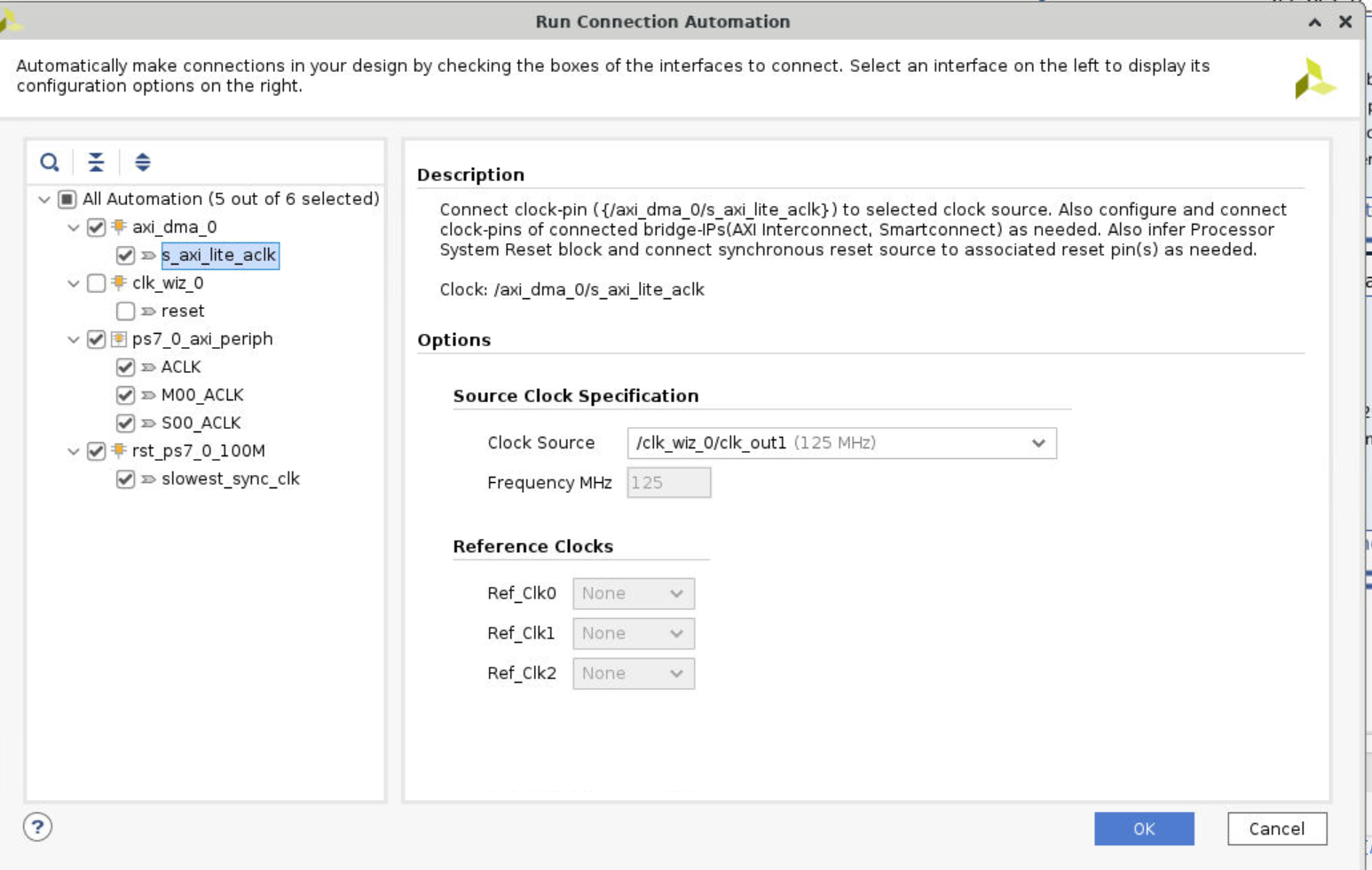
s_axi_lite_aclk, and change theclock sourceto/clk_wiz_0/clk_out1. Repeat this operation to other clock signals.
-
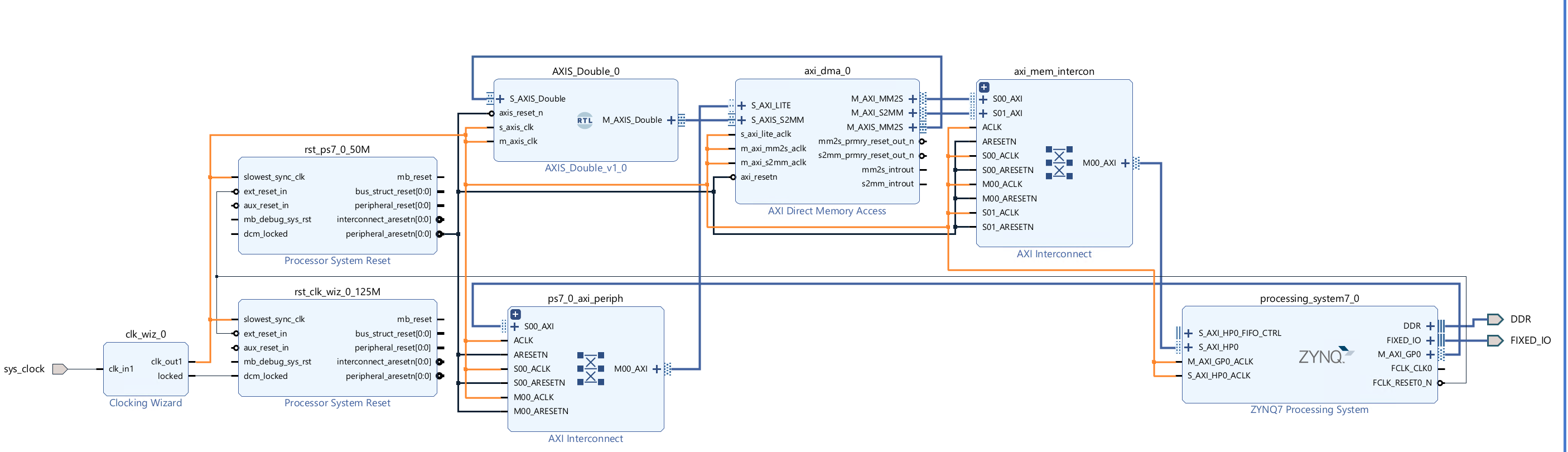
Connect the
M_AXIS_DoubleofAXIS_Double_v1_0to theS_AXIS_S2MMofAXI Direcr Memory Access, andM_AXIS_MM2Sof DMA toS_AXIS_DoubleofAXIS_Double. Then clickRun Connection Automation -
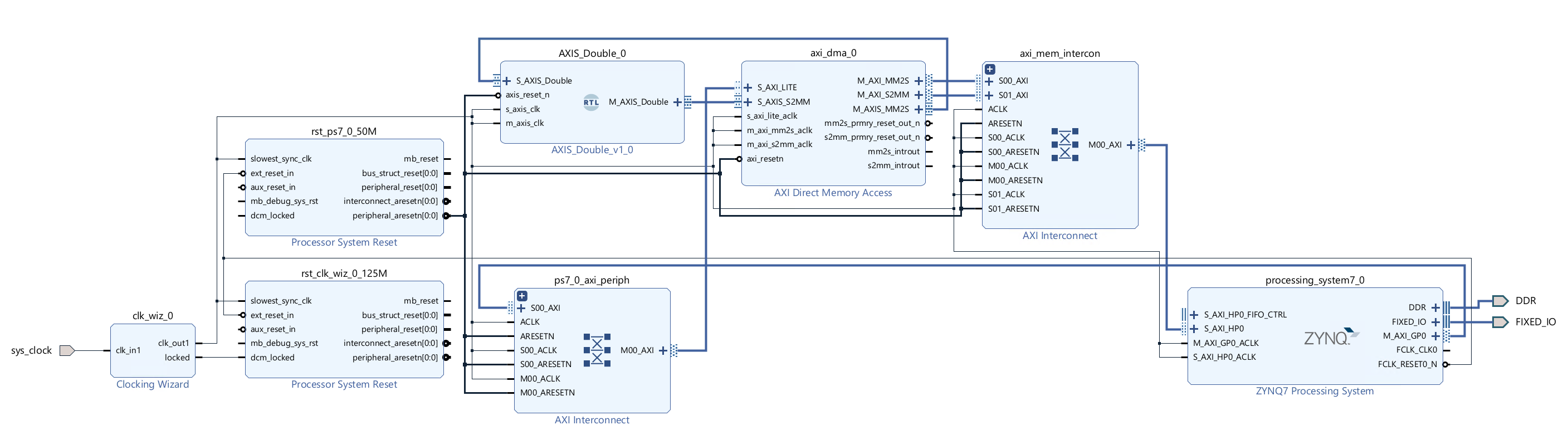
The whole diagram will show like the following.
- Create wrapper and set it as top
Run synthesis, Implementation and generate bitstream
It may shows some errors about I/O Ports, please fix them.
Download the bitstream file to PYNQ
from pynq import Overlay
from pynq import allocate
import numpy as np
ol = Overlay("design_1_wrapper.bit")
ol.download()
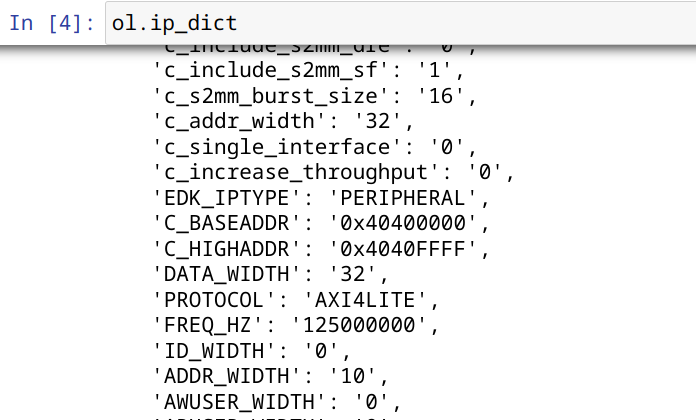
We can check the IPs in this overlay using the IP dictionary (ip_dict). Note that the output you see here is cut short. The full optput can be viewed if you run this code on your PYNQ enabled board.
ol.ip_dict
Create DMA instances
Using the labels for the DMAs listed above, we can create two DMA objects.
dma = ol.axi_dma_0
dma_send = dma.sendchannel
dma_recv = dma.recvchannel
Read DMA
The first step is to allocate the buffer. pynq.allocate will be used to allocate the buffer, and NumPy will be used to specify the type of the buffer.
data_size = 100
input_buffer = allocate(shape=(data_size,), dtype=np.uint32)
output_buffer = allocate(shape=(data_size,), dtype=np.uint32)
output_buffer[:] = 0
for i in range(data_size):
input_buffer[i] = i
Print the value of input_buffer, you will see:
for i in range(10):
print(input_buffer[i])
dma_recv.transfer(output_buffer)
dma_send.transfer(input_buffer)
output_buffer.flush()
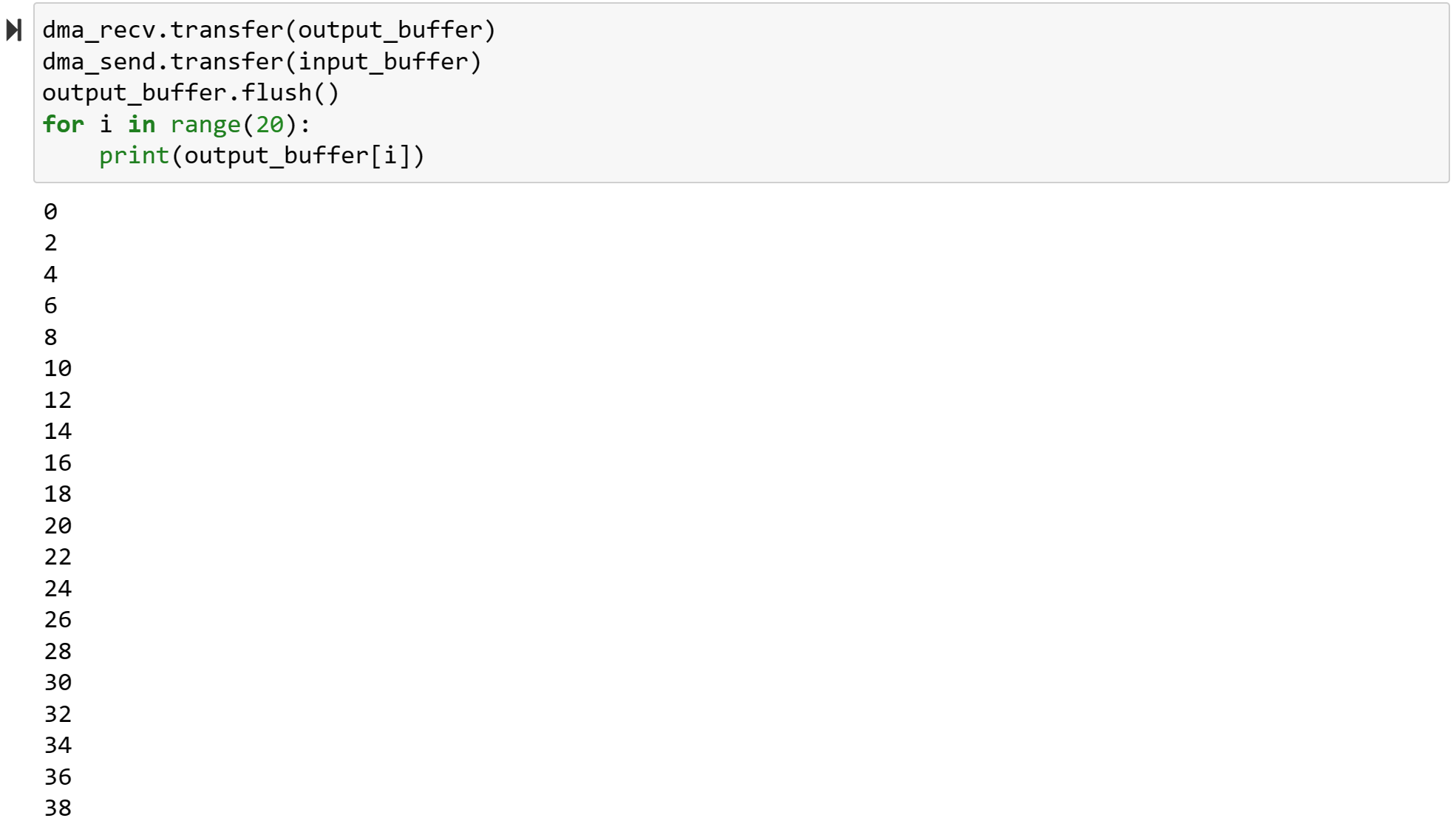
for i in range(20):
print(output_buffer[i])
We will see: